
Mathematik-Online-Lexikon:
|
|
[Home] [Lexikon] [Aufgaben] [Tests] [Kurse] [Begleitmaterial] [Hinweise] [Mitwirkende] [Publikationen] |
|
|
Mathematik-Online-Lexikon: | ||
Codes | ||
| A B C D E F G H I J K L M N O P Q R S T U V W X Y Z | Übersicht |
Allgemeine Codes.
Gegeben sei eine endlich Menge
![]() von
von
![]() Elmenten, genannt Alphabet. Ein Code
Elmenten, genannt Alphabet. Ein Code
![]() der
Länge
der
Länge
![]() ist eine Teilmenge von
ist eine Teilmenge von
![]() .
.
Die Informationsrate von
![]() ist
ist
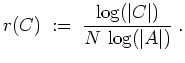
Für
![]() ist die Hamming-Distanz von
ist die Hamming-Distanz von
![]() und
und
![]() definiert durch
definiert durch
Ein Minimal-Distanz-Decodierer (MDD) liefert zu jedem
![]() ein
Codewort
ein
Codewort
![]() , das zu
, das zu
![]() minimale Hamming-Distanz hat. Ein MDD ist also eine
Funktion
minimale Hamming-Distanz hat. Ein MDD ist also eine
Funktion
![]() mit
mit
Zwei Codes
![]() und
und
![]() heißen äquivalent, falls es eine Permutation
heißen äquivalent, falls es eine Permutation
![]() auf
auf
![]() so gibt, daß
so gibt, daß
![]() eine Bijektion von
eine Bijektion von
![]() nach
nach
![]() darstellt.
Äquivalente Codes haben dieselbe Informationsrate und dieselbe Minimaldistanz.
darstellt.
Äquivalente Codes haben dieselbe Informationsrate und dieselbe Minimaldistanz.
Ziel der Codierungstheorie ist es, Codes mit großem Minimalabstand bei großer Informationsrate zu finden.
Lineare Codes.
Sei im folgenden
![]() ein endliche Körper und
ein endliche Körper und
![]() der Vektorraum der Dimension
der Vektorraum der Dimension
![]() über
über
![]() . Ein Untervektorraum
. Ein Untervektorraum
![]() von
von
![]() heißt linearer Code.
Ist
heißt linearer Code.
Ist
![]() eine Basis von
eine Basis von
![]() , geschrieben als Zeilenvektoren, so heißt
die Matrix
, geschrieben als Zeilenvektoren, so heißt
die Matrix
![]() mit den Zeilen
mit den Zeilen
![]() eine Erzeugermatrix
von
eine Erzeugermatrix
von
![]() .
.
Ein linearer Code
![]() der Dimension
der Dimension
![]() hat die Informationsrate
hat die Informationsrate
![]() . Ist die Minimaldistanz
. Ist die Minimaldistanz
![]() , so spricht man von einem
, so spricht man von einem
![]() -Code.
Der Minimalabstand eines linearen Codes ist gleich der minimalen Anzahl der
Nichtnulleinträge eines Codeworts ungleich dem Nullvektor.
-Code.
Der Minimalabstand eines linearen Codes ist gleich der minimalen Anzahl der
Nichtnulleinträge eines Codeworts ungleich dem Nullvektor.
Sei
![]() ein linearer Code von Dimension
ein linearer Code von Dimension
![]() , dann ist
, dann ist
![]() äquivalent zu einem
linearen Code mit einer Erzeugermatrix
äquivalent zu einem
linearen Code mit einer Erzeugermatrix
![]() , wobei
, wobei
![]() die
Einheitsmatrix bezeichnet.
die
Einheitsmatrix bezeichnet.
Für einen linearen Code
![]() mit einer Erzeugermatrix
mit einer Erzeugermatrix
![]() ist
eine Prüfmatrix durch
ist
eine Prüfmatrix durch
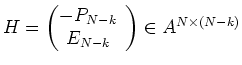 gegeben.
gegeben.
Allgemein heißt jede Matrix
![]() , die
, die
Ist
![]() ein Codewort und
ein Codewort und
![]() ein Übermittlungsfehler, so liefert
die Multiplikation mit der Prüfmatrix
ein Übermittlungsfehler, so liefert
die Multiplikation mit der Prüfmatrix
Ein MDD für einen linearen Code
![]() ist definiert durch
ist definiert durch
![]() wobei
wobei
![]() in Abhängigkeit von
in Abhängigkeit von
![]() so gewählt ist,
daß das Syndrom
so gewählt ist,
daß das Syndrom
![]() wird, und so, daß
wird, und so, daß
![]() .
.
(Ist
![]() größer als die Übertragungsfehlerzahl, so wird man für
größer als die Übertragungsfehlerzahl, so wird man für
![]() wie oben auf diese Weise auf
wie oben auf diese Weise auf
![]() stoßen.)
stoßen.)
Binäre Hamming-Codes.
Ein binärer Hamming-Code der Länge
![]() (mit
(mit
![]() ) ist bestimmt durch
eine Prüfmatrix
) ist bestimmt durch
eine Prüfmatrix
![]() , wobei in den Zeilen gerade alle Vektoren
von
, wobei in den Zeilen gerade alle Vektoren
von
![]() stehen. Hamming-Codes sind
stehen. Hamming-Codes sind
![]() -Codes.
Der für die Praxis
entscheidende Vorteil ist die einfache Fehlerkorrektur bei der Decodierung.
Bei binären Hamming-Codes ist
für
-Codes.
Der für die Praxis
entscheidende Vorteil ist die einfache Fehlerkorrektur bei der Decodierung.
Bei binären Hamming-Codes ist
für
![]() das Syndrom
das Syndrom
![]() an höchstens einer Stelle nicht Null, und
der (eindeutige) MDD ist gegeben durch
an höchstens einer Stelle nicht Null, und
der (eindeutige) MDD ist gegeben durch
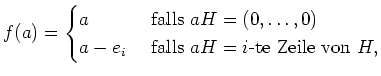
Beispiele:
| automatisch erstellt am 25. 1. 2006 |